

Selon le MIT, certaines langues jamais traduites pourraient être les prochaines à bénéficier des avancées du “Machine Learning”.
Une pierre ancienne découverte par Arthur Evans
En 1886, l’archéologue britannique Arthur Evans découvre une pierre ancienne portant une curieuse série d’inscriptions dans une langue inconnue. La pierre venait de l’île méditerranéenne de Crète, et Evans s’y rendit immédiatement pour y dénicher d’autres preuves. Il trouva rapidement de nombreuses pierres et tablettes portant des inscriptions similaires et les data vers 1400 avant notre ère.
Cela a fait de cette inscription l’une des premières formes d’écriture jamais découvertes. Evans a fait valoir que sa forme linéaire était clairement dérivée de lignes rudimentaires appartenant à la naissance de l’art. Ceci établit son importance dans l’histoire de la linguistique.
Deux écritures sur une même tablette
Lui et d’autres ont plus tard déterminé que les pierres et les tablettes étaient écrites dans deux écritures différentes. La plus ancienne, appelée Linéaire A (Linear A) , date entre 1800 et 1400 avant notre ère, lorsque l’île était dominée par la civilisation minoenne de l’âge du bronze.
L’autre écriture, Linear B, est plus récente, n’apparaissant qu’après 1400 avant notre ère. Alors que l’l’île fut conquise par les Mycéniens du continent grec.
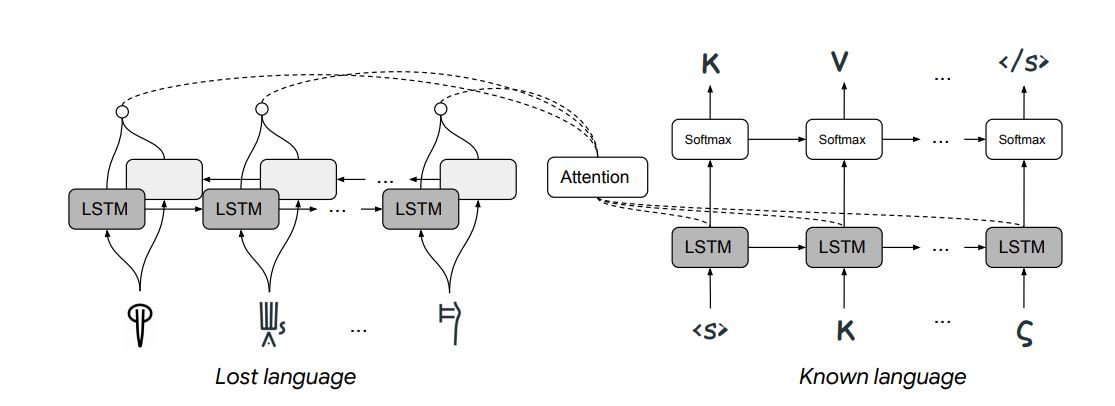
Les avancées de Michaël Ventris
Evans et d’autres ont essayé pendant de nombreuses années de déchiffrer les anciennes écritures, mais les langues perdues ont résisté à toutes les tentatives. Le problème est resté sans solution jusqu’en 1953, lorsqu’un linguiste amateur nommé Michael Ventris a déchiffré le code pour Linear B.
Sa solution s’est construite sur deux avancées décisives. Tout d’abord, Ventris a supposé que beaucoup des mots répétés dans le vocabulaire de Linear B étaient des noms de lieux sur l’île de Crète. Cela s’est avéré exact.

Sa deuxième percée a été de supposer que l’écriture a enregistré une forme primitive du grec ancien. Cette intuition lui a immédiatement permis de déchiffrer le reste de la langue. Ce faisant, Ventris a montré que le grec ancien est apparu pour la première fois sous forme écrite plusieurs siècles plus tôt qu’on ne le pensait auparavant.
Le travail de Ventris a été une grande réussite. Mais l’écriture plus ancienne, Linear A, est restée jusqu’à ce jour l’un des grands casse-tête dans la linguistique.
En quelques années seulement, l’étude de la linguistique a été révolutionnée par la disponibilité d’énormes bases de données annotées et de techniques permettant aux machines d’en tirer des enseignements
Il n’est pas difficile d’imaginer que les progrès récents de la traduction automatique pourront aider à son déchiffrage. En quelques années seulement, l’étude de la linguistique a été révolutionnée par la disponibilité d’énormes bases de données annotées et de techniques permettant aux machines d’en tirer des enseignements. Par conséquent, la traduction automatique d’une langue à une autre s’est améliorée. Et bien qu’elles ne soient pas parfaites, ces méthodes ont fourni une toute nouvelle façon d’appréhender les langues.
Les travaux de Jiaming Luo, Regina Barzilay er Yuan Cao
C’est le cas de Jiaming Luo et Regina Barzilay du MIT et de Yuan Cao du laboratoire d’IA de Google à Mountain View, en Californie. Cette équipe a mis au point un système de “Machine Learning” capable de déchiffrer les langues perdues, et elle l’a démontré en le faisant déchiffrer Linear B – la première fois que cela a été fait automatiquement. L’approche qu’ils ont utilisée était très différente des techniques standard de traduction automatique.
Des mots liés les uns aux autres
D’abord un peu de contexte. L’idée maîtresse de la traduction automatique est de comprendre que les mots sont liés les uns aux autres de la même façon, quelle que soit la langue utilisée.
Le processus commence donc par l’établissement de ces relations pour une langue spécifique. Cela nécessite d’énormes bases de données textuelles. Une machine recherche alors ce texte pour voir combien de fois chaque mot apparaît à côté d’un mot sur deux.
Ce motif d’apparences est une signature unique qui définit le mot dans un espace de paramètres multidimensionnel. En effet, le mot peut être considéré comme un vecteur dans cet espace. Et ce vecteur agit comme une contrainte puissante sur la façon dont le mot peut apparaître dans n’importe quelle traduction produite par la machine.
Ces vecteurs obéissent à des règles mathématiques simples. Par exemple : roi – homme + femme = reine. Et une phrase peut être considérée comme un ensemble de vecteurs qui se suivent les uns après les autres pour former une sorte de trajectoire à travers cet espace.
Le mapping mot par mot d’une langue à une autre
L’idée clé qui permet la traduction automatique est que les mots dans différentes langues occupent les mêmes points dans leurs espaces de paramètres respectifs. Cela permet de mapper une langue entière sur une autre langue avec une correspondance mot à mot.
De cette façon, le processus de traduction des phrases devient le processus de recherche de trajectoires similaires à travers ces espaces. La machine n’a même pas besoin de “savoir” ce que signifient les phrases.
Ce processus repose essentiellement sur les grands ensembles de données. Mais il y a quelques années, une équipe allemande de chercheurs a montré comment une approche similaire avec des bases de données beaucoup plus petites pouvait aider à traduire des langues beaucoup plus rares qui manquent de grandes bases de données de texte.
L’astuce est de trouver une autre façon de contraindre l’approche de la machine qui ne repose pas sur la base de données.
Déchiffrer des langues perdues
Aujourd’hui, Luo et ses collègues sont allés plus loin pour montrer comment la traduction automatique peut déchiffrer des langues qui ont été complètement perdues. La contrainte qu’ils utilisent est liée à la façon dont les langues sont connues pour évoluer dans le temps.
L’idée est que n’importe quelle langue ne peut changer que d’une certaine façon – par exemple, les symboles dans les langues liées apparaissent avec des distributions similaires, les mots liés ont le même ordre de caractères, et ainsi de suite. Avec ces règles contraignant la machine, il devient beaucoup plus facile de déchiffrer une langue, à condition que la langue ancestrale soit connue.
Luo et son équipe ont mis la technique à l’épreuve avec deux langues perdues, Linear B et Ugaritic. Les linguistes savent que Linear B code une version ancienne du grec ancien et que l’ougaritique, découvert en 1929, est une forme ancienne de l’hébreu.
Une précision de traduction remarquable
Compte tenu de cette information et des contraintes imposées par l’évolution linguistique, la machine de Luo et de son équipe est capable de traduire les deux langues avec une précision remarquable. “Nous avons été capables de traduire correctement 67,3% des cognates de Linear B en leurs équivalents grecs dans le scénario de déchiffrement,” disent-ils. “Pour autant que nous sachions, notre expérience est la première tentative de déchiffrage automatique de Linear B.”
La traduction automatique portée à un nouveau niveau
C’est un travail impressionnant qui porte la traduction automatique à un nouveau niveau. Mais cela soulève aussi la question intéressante d’autres langues perdues, en particulier celles qui n’ont jamais été déchiffrées, comme “Linear A”.
Dans cet article, Linear A se distingue par son absence. Luo et al. n’en parlent même pas, mais il faut qu’il occupe une place importante dans leur réflexion, comme c’est le cas pour tous les linguistes. Pourtant, des percées significatives sont encore nécessaires avant que ce script ne puisse être traduit automatiquement.
Par exemple, personne ne sait quelle langue Linear A code. Les tentatives pour le déchiffrer en grec ancien ont toutes échoué. Et sans le langage ancestral, la nouvelle technique ne fonctionne pas.
Le grand avantage des approches basées sur le “machine learning” est qu’elles permettent de tester une langue après l’autre rapidement sans se fatiguer
Mais le grand avantage des approches basées sur le “machine learning” est qu’elles permettent de tester une langue après l’autre rapidement sans se fatiguer. Il est donc tout à fait possible que Luo et ses collègues s’attaquent à la “Linear A” avec une approche “en force” – ils tentent simplement de la déchiffrer dans toutes les langues pour lesquelles la traduction automatique fonctionne déjà.
Si cela fonctionne, ce sera une réussite impressionnante, une réussite dont même Michael Ventris serait étonné.
Mais rassurons nous, apprendre les langues étrangères dès le plus jeune âge est plus qu’une nécessité. Si la traduction automatique s’améliore chaque jour, rien ne remplacera jamais la culture des civilisations et la créativité des auteurs. En cette période estivale : posez-vous et continuez à lire !
Source : MIT Technology Review
Ref: arxiv.org/abs/1906.06718 : Neural Decipherment via Minimum-Cost Flow: from Ugaritic to Linear B